Chargement de l'article...
Écriture : Victor Connes et Nicolas Dugué
Relecture scientifique : Manon Cassier et Loïc Grobol
Relecture de forme : Lucile Riaboff et Mathilde Ruby
Temps de lecture : environ 10 minutes.
Thématiques : Traitement automatique du langage (Linguistique et Informatique)
Publication originale : Bolukbasi T., et al., Man is to computer programmer as woman is to homemaker? debiasing word embeddings. NIPS Proceedings β, 2016
Le traitement automatique du langage tente de résoudre des tâches comme la traduction, les systèmes de dialogue humain-machine ou la catégorisation de documents. Ces systèmes informatiques ont généralement besoin de représentations du vocabulaire humain compréhensibles par la machine. Appris par des algorithmes exploitant de grands corpus de données textuelles, les plongements lexicaux partagent ces propriétés. Cependant, ces représentations reproduisent les stéréotypes latents dans les gros corpus utilisés, comme les stéréotypes de genre évoqués dans l’article de Bolukbasi et ses collègues.
Connaissez-vous les néologismes ? Ce sont la plupart du temps des mots nouveaux, comme le célèbre pianocktail de Boris Vian. Ici, ce néologisme est un mot-valise, il est facile de deviner son sens en rapport avec le piano et les cocktails. Dans L’écume des jours, le pianocktail est un piano qui s’inspire du morceau interprété sur son clavier pour élaborer un cocktail qui en rappelle les émotions.
Deviner le sens d’un mot ? Aidons-nous du contexte !
En revanche, le néologisme agélaste attribué à Rabelais est plus difficile à comprendre, même si la forme du mot peut nous donner son sens lorsque l’on a fait du grec ancien. Mais alors, que faire si l’on n’y connaît rien en grec ancien ? On peut s’aider du contexte dans lequel apparaît le mot. En effet, les mots qui entourent agélaste vont nous aider à déterminer son sens, comme dans les trois phrases qui suivent :
- « N’ayant jamais entendu le rire de Dieu, les agélastes sont persuadés que la vérité est claire. » (Milan Kundera)
- Isaac Newton est l’archétype de l’agélaste, il n’aurait ri qu’une seule fois dans sa vie.
- Le maréchal Joukov écrit dans ses mémoires que « Rares sont ceux qui ont vu rire Staline » décrivant Staline comme un célèbre agélaste.
Ainsi, on voit dans cet exemple que le mot rire, ou sa forme conjuguée ri apparaît dans les trois phrases. Le sens d’agélaste aurait ainsi à voir avec le rire. C’est cette idée qui est reprise dans l’hypothèse de Firth : « a word is characterized by the company it keeps », traduit par « un mot est caractérisé par les mots qui l’entourent » [1]. Un agélaste est en réalité un individu dénué d’humour, qui ne rit presque jamais, et le contexte dans lequel ce mot est employé nous a permis de le deviner.
Prenons un second exemple : le cas de blavouiller. Pour ce néologisme introduit par l’écrivain Céline, la forme du mot n’est pas immédiatement informative de son sens. En revanche, la façon dont il est utilisé va également pouvoir nous renseigner. Posez-vous la question des mots par lesquels vous pourriez le remplacer en lisant les phrases suivantes :
- Cessez de blavouiller pendant le cours !
- Trêve de blavouillage, passons aux choses sérieuses !
- Dès qu’elle arrivait, sans un embarras, à l’aise comme chez un ami, c’était pour blavouiller, d’un flot intarissable. (Inspiré de L’oeuvre d’Émile Zola)
Il semble facile de remplacer blavouiller par bavarder n’est-ce pas ? C’est en effet parce que blavouiller signifie « parler à tort et à travers » (en réalité, maintenant que l’on connait son sens, on peut se rendre compte que le mot est un mélange entre blablater et baver, blavouiller).
Cette façon de déterminer le sens d’un mot en le remplaçant par un autre (Figure 1) nous est expliqué par Harris. En effet, d’après lui, deux mots dont le sens est proche auront tendance à apparaître dans un contexte similaire [2].

Les programmes informatiques utilisent également le contexte
Grâce aux travaux de Harris et Firth, les chercheur·ses en linguistique computationnelle [*] et en informatique ont développé des méthodes qui permettent de stocker les mots sur l’ordinateur sous une forme spécifique, de façon à ce qu’ils puissent être utilisés par des algorithmes. C’est ce qu’on appelle des plongements lexicaux. Ils sont utilisés par exemple pour faire de la traduction automatique, de la transcription de la parole, ou encore dans les chatbots, ces programmes capables de répondre à des questions sur un sujet précis. Pour obtenir ces plongements lexicaux, les chercheur·ses procèdent en trois étapes.
Dans la première étape, iels ont d’abord besoin de réunir de grands corpus textuels, c’est-à-dire de nombreux documents écrits par des humain·es et numérisés (Figure 2). Ces contenus peuvent être des livres numérisés comme les Google Books, des contenus encyclopédiques libres tel que Wikipedia, des transcriptions de la partie audio de vidéos comme celles stockées par l’INA, ou encore des compilations d’articles de grands journaux écrits.

La seconde étape consiste pour les chercheur·ses à écrire des algorithmes qui, pour chaque mot, déterminent le contexte dans lequel ils sont utilisés dans ces documents : on parle de co-occurrences. Par exemple, dans notre corpus de trois phrases ci-dessous, on remarque que agélaste et rire co-occurrent deux fois, trois fois si l’on compte également le mot ri qui est la forme conjuguée de rire (Figure 3).

Dans la troisième étape, les chercheur·ses mettent en oeuvre directement le travail de Harris et Firth. Ainsi, iels créent des algorithmes qui produisent des plongements lexicaux en utilisant le fait que, plus deux mots co-occurrent ensemble, plus ils ont de chances d’être proches au niveau du sens (Firth). De plus, ces algorithmes utilisent aussi le fait que plus les co-occurrences de deux mots sont semblables (c’est-à-dire qu’ils semblent interchangeables dans le corpus), plus ils ont de chances d’être proches au niveau sens (Figure 1).
Pour visualiser (en simplifiant) ce qu’est un plongement lexical, imaginez une immense feuille de papier. On dispose de plusieurs milliers de mots, et on souhaite tous les écrire sur cette feuille en suivant les règles de Firth et Harris :
- plus deux mots co-occurrent, plus ils doivent être proches sur la feuille (et inversement) ;
- plus deux mots semblent interchangeables, plus ils doivent être proches sur la feuille (et inversement).
En réalité, ces deux règles sont au coeur de la philosophie des algorithmes qui permettent d’obtenir les plongements lexicaux, et ainsi de stocker les mots en fonction de leur sens (Figure 4).
Les plongements lexicaux sont-ils misogynes ?
Bolukbasi et ses collègues nous disent que dans le langage, certains mots sont genrés par définition. On ne s’intéresse pas ici au genre dit grammatical, à savoir si le mot est masculin ou féminin, mais si la définition du mot l’associe à un genre. Par exemple, frère est un mot associé au genre masculin par définition, tandis que soeur l’est au genre féminin. Le reste du vocabulaire est considéré par les auteurs comme neutre : sa définition ne l’associe pas à un genre spécifique. Par exemple, médecin, philosophe ou libraire peuvent s’employer pour désigner une personne, peu importe son genre. C’est en général le cas pour les noms de postes, et c’est pour cela que Bolukbasi et ses collègues les utilisent pour étudier les stéréotypes de genre présents dans les plongements lexicaux. En effet, les auteur·rices considèrent qu’il y a un stéréotype, ou un biais, lorsqu’un mot dit neutre au sens de leur catégorisation est nettement plus similaire à un genre qu’à l’autre.
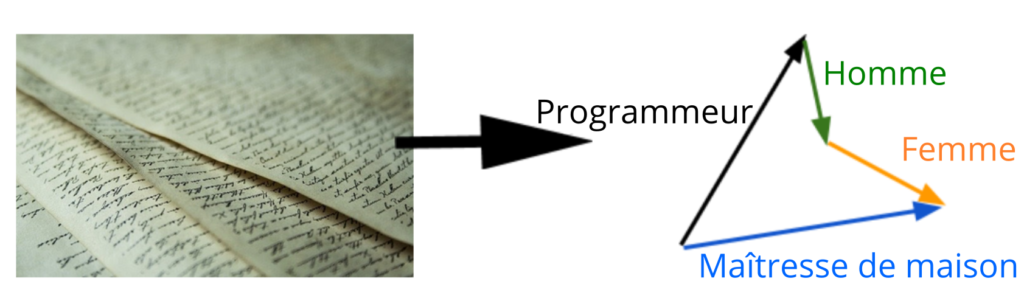
Dans la publication qui nous intéresse ici, Bolukbasi et ses collègues considèrent alors des plongements lexicaux obtenus en utilisant comme corpus (Figure 2) des données de média en anglais issues de Google news : un très grand nombre de mots se retrouvent ainsi rangés par l’algorithme (Figure 4) selon leurs co-occurrences (Figure 3) dans ce corpus. Iels utilisent ensuite une liste de 327 professions et recherchent les métiers dans cette liste qui sont les plus proches, dans les textes (= sur la feuille de papier), de he (le pronom il en français), ou she (le pronom elle).
Les cinq mots de la liste qui sont les plus similaires à he (il) sont dans l’ordre maestro (maître), skipper (skipper), protege (protégé), philosopher (philosophe), captain (capitaine) ; les cinq mots les plus proches de she (elle) sont housemaker (ménager⋅e), nurse (infirmier⋅e), receptionist (réceptionniste), librarian (bibliothécaire), socialite (mondain⋅e). Comme on peut le voir, ces résultats semblent refléter une vision misogyne de ces métiers. Pour autant, est-ce la faute des algorithmes ? Rien ne permet de l’affirmer pour le moment. Au contraire, il est probable que ces résultats soient le reflet des co-occurrences issues du corpus de textes de Google news, et donc qu’ils mettent en lumière des stéréotypes très ancrés dans nos sociétés. Pour confirmer cette première hypothèse, Bolukbasi et ses collègues proposent une expérimentation supplémentaire basée sur la découverte d’analogies en exploitant les plongements lexicaux.
Une façon de stocker les mots qui permet de retrouver les analogies
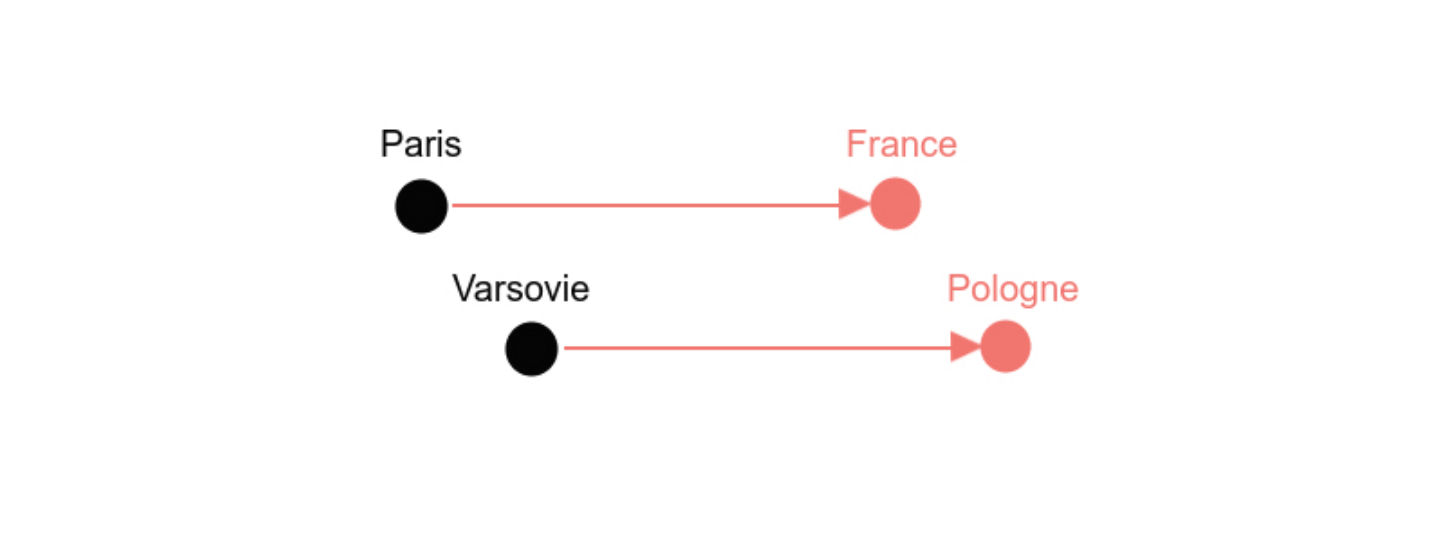
Considérons par exemple l’analogie représentée par le concept de capitale : Paris est à la France ce que Varsovie est à la Pologne. Ou encore l’analogie représentée par le concept féminin : sœur est au frère ce que reine est au roi.
Comment sont retrouvées ces analogies ? Les méthodes qui créent les plongements lexicaux rangent les mots automatiquement d’une façon bien spécifique de façon à pouvoir les retrouver [3]. Reprenons notre immense feuille de papier sur laquelle les mots ont été écrits en suivant les règles de Firth et Harris. Supposons que nous tracions un trait du mot Paris vers le mot France. S’il y a analogie, alors en reproduisant ce même trait à partir de Varsovie, on devrait tomber sur le mot Pologne. Ainsi, d’après la Figure 5, pour trouver le pays associé à une capitale, il suffit de trouver sa capitale puis de se déplacer vers la droite de la même distance qui existe entre Paris et France. C’est comme si le nom d’un pays était accroché à sa capitale par une tige rigide : peu importe le placement de la capitale sur notre feuille de papier, le pays est toujours à la même distance, dans la même direction.
Des analogies misogynes ? [**]
Bolukbasi et ses collègues mettent en lumière un certain nombre d’analogies (traduites de l’anglais vers le français) choquantes : elle est à il, ce que la designeuse d’intérieur est à l’architecte, ou ce que l’infirmière est au chirurgien, ou encore ce que la ménagère est au commerçant. Ainsi, selon les plongements lexicaux, être chirurgien pour un homme équivaudrait à être infirmière pour une femme. De plus, dans les trois cas présentés, le nom de métier associé au mot féminin elle est systématiquement associé à un métier qui requiert moins de diplômes, ou donne accès à un salaire plus faible en moyenne que le nom de métier associé au masculin il. Il est important de rappeler que les corpus utilisés par Bolukbasi et ses collègues sont issus de l’agrégation de nombreux documents produits par des humain·es. Les plongements lexicaux qui sont appris sur ces corpus par les algorithmes sont ainsi le reflet de l’usage qui a été fait du vocabulaire par ces humain·es, et les analogies découvertes reproduisent donc des stéréotypes humains.
Conséquences de ces stéréotypes sur les algorithmes utilisés dans les applications du quotidien
Les plongements lexicaux sont utilisés pour de nombreuses applications, et donc, ces stéréotypes peuvent théoriquement se propager à ces applications. Un exemple parlant est celui du chatbot Tay, programmé par Microsoft, qui a tenu des propos racistes à cause du corpus utilisé par l’algorithme. Ce genre de préoccupation est au cœur d’un certain nombre de problématiques de recherche sur des algorithmes équitables (fair en anglais). L’objectif de travaux comme ceux que nous évoquons est de détecter les stéréotypes existants afin d’éviter par la suite toute discrimination au sein des algorithmes. Discrimination présente par exemple dans le cadre de COMPAS, un algorithme utilisé par le système judiciaire de certains états des Etats-Unis [4] pour prédire les chances de récidives des criminel⋅le⋅s, en utilisant leur dossier (stéréotypes ethniques et religieux [5]).
[*] Discipline scientifique à la croisée de la linguistique et de l’informatique qui vise à modéliser le langage à l’aide de méthodes mathématiques et logiques de manière à le rendre compréhensible par une machine.
[**] Les analogies présentées dans ce paragraphe sont issues d’un article en langue anglaise. Par souci de lisibilité et pour faciliter la compréhension, les analogies ont été genrées pendant le processus de traduction. Néanmoins, une traduction au plus proche des résultats observés sur la langue anglaise devrait être neutre. Ainsi l’analogie : « elle est à il ce que la designeuse d’intérieur est à l’architecte » serait traduite par « elle est à il ce que le·la designeur·se d’intérieur est à l’architecte ».
[1] Firth J.R., « A synopsis of linguistic theory 1930-1955 ». Studies in Linguistic Analysis, 1957. [Livre de science]
[2] Harris Z., « Distributional structure ». Word, 1954. [Livre de science]
[3] GloVe: Global Vectors for Word Representation. Pennington J., et al., 2014. [Page de présentation de l’algorithme]
[4] Pour prédire la récidive, l’intérêt limité des algorithmes. Sciences et avenir, 2018. [Article de presse]
[5] Wang H., et al., An Empirical Study on Learning Fairness Metrics for COMPAS Data with Human Supervision. NeurIPS, 2019. [Publication scientifique]
Publié le 21/09/2020
 Victor Connes et Nicolas Dugué/Papier-Mâché/CC BY-NC-SA 4.0 2020
Victor Connes et Nicolas Dugué/Papier-Mâché/CC BY-NC-SA 4.0 2020Texte et images, à l’exception des images soumises à droits d’auteurs différents : voir au cas par cas en légende.
Écriture : Victor Connes et Nicolas Dugué
Relecture scientifique : Manon Cassier et Loïc Grobol
Relecture de forme : Lucile Riaboff
Temps de lecture : environ 16 minutes.
Thématiques : Traitement automatique du langage (Linguistique et Informatique)
Publication originale : Bolukbasi T., et al., Man is to computer programmer as woman is to homemaker? debiasing word embeddings. NIPS Proceedings β, 2016
Le traitement automatique du langage tente de résoudre des tâches comme la traduction, les systèmes de dialogue humain-machine ou la catégorisation de documents. Ces systèmes informatiques ont généralement besoin de représentations du vocabulaire humain compréhensibles par la machine. Appris par des algorithmes exploitant de grands corpus de données textuelles, les plongements lexicaux partagent ces propriétés. Cependant, ces représentations reproduisent les stéréotypes latents dans les gros corpus utilisés, comme les stéréotypes de genre évoqués dans l’article de Bolukbasi et ses collègues.
Le traitement automatique du langage naturel est un domaine à la croisée de l’informatique et de la linguistique qui inclut la résolution automatique de tâches comme la traduction d’une langue source vers une langue cible, la catégorisation de documents selon leur thématique, les systèmes de dialogue humain-machine ou chatbots. Pour chacune de ces tâches, on considère des approches différentes mais pour lesquelles il est systématiquement nécessaire de représenter en amont le vocabulaire humain sous forme intelligible par la machine. De plus, on souhaite que cette représentation encode les propriétés sémantiques et syntaxiques de ce vocabulaire. Lorsque ces représentations, appelées plongements lexicaux, sont données en entrée des algorithmes d’apprentissage automatique, on observe par rapport aux approches plus naïves une amélioration des résultats en sortie, par exemple en donnant de meilleures traductions automatiques. En informatique, l’information est représentée sous forme de nombres pour de tels problèmes, et c’est ce que nous détaillons dans les paragraphes suivants.
Représenter le sens des mots : les plongements lexicaux
Représenter le vocabulaire dans un espace mathématique
Pour représenter le vocabulaire  d’un corpus documentaire
d’un corpus documentaire  , on peut par exemple choisir de compter les co-occurrences de toutes les paires de mots de , c’est-à-dire le nombre de fois que les deux mots de chaque paire apparaissent au sein d’un même contexte (par exemple d’une même phrase) dans . On enregistre ces co-occurrences au sein d’un tableau à double-entrée que l’on appelle matrice de co-occurrence
, on peut par exemple choisir de compter les co-occurrences de toutes les paires de mots de , c’est-à-dire le nombre de fois que les deux mots de chaque paire apparaissent au sein d’un même contexte (par exemple d’une même phrase) dans . On enregistre ces co-occurrences au sein d’un tableau à double-entrée que l’on appelle matrice de co-occurrence  . Cette matrice a
. Cette matrice a  lignes (
lignes ( ) et colonnes, et
) et colonnes, et  est égal au nombre de co-occurrences des mots
est égal au nombre de co-occurrences des mots  et
et  .
.
En général, on considère que les lignes de constituent la représentation informatique des mots , via leur co-occurrence. Chacune d’entre elles est un vecteur donnant la description d’un mot dans l’espace de représentation à dimensions indiquant les co-occurrences entre les mots du vocabulaire.
Utiliser les co-occurrences dans de grands corpus pour obtenir des vecteurs sémantiques
Le linguiste Firth nous dit en 1957 : « a word is characterized by the company it keeps » (i.e. « un mot est caractérisé par les mots qui l’entourent ») [1]. L’hypothèse consiste à dire que pour caractériser le sens d’un mot, sa sémantique, il suffit de considérer les mots qui l’accompagnent le plus fréquemment dans le texte. La matrice de co-occurrences précédemment présentée est un moyen de modéliser cette hypothèse.
En pratique, pour disposer de vecteurs capables de bien représenter la sémantique du vocabulaire, il est préférable d’appliquer la PPMI (Positive Pointwise Mutual Information) à toutes les paires de mots  de cette matrice [2] :
de cette matrice [2] :

La PPMI est une mesure permettant de mettre en valeur les paires de mots les plus significatives statistiquement en pondérant la mesure de co-occurrence par la fréquence de chaque mot de la paire. En effet, supposons que les mots d’un corpus soient des objets physiques. Si l’on prend chacun de ces mots et qu’on les place dans un sac que l’on mélange avant de jeter tous les mots sur une feuille, alors on obtient un nouveau corpus aléatoire. Deux mots très présents dans le sac ont plus de chance de se retrouver côte à côte dans ce corpus aléatoire. C’est ce qui est modélisé par le ratio entre  , la fréquence de co-occurrences réelles, et
, la fréquence de co-occurrences réelles, et  , une estimation de la fréquence de co-occurrences dans ce corpus aléatoire. Le logarithme projette ce ratio entre moins l’infini et plus l’infini. Plus deux mots co-occurrent, plus le score tend vers plus l’infini. Inversement, moins les mots co-occurrent, plus le logarithme du ratio sera proche de 0. La fonction
, une estimation de la fréquence de co-occurrences dans ce corpus aléatoire. Le logarithme projette ce ratio entre moins l’infini et plus l’infini. Plus deux mots co-occurrent, plus le score tend vers plus l’infini. Inversement, moins les mots co-occurrent, plus le logarithme du ratio sera proche de 0. La fonction  permet donc de mettre le score à 0 dans ce dernier cas. On évite ainsi d’accorder trop de poids à des mots très fréquents, mais parfois peu intéressants sémantiquement, comme des mots de liaison (par exemple et, ou, car). On applique ainsi la PPMI à chaque valeur de la matrice pour obtenir les vecteurs PPMI.
permet donc de mettre le score à 0 dans ce dernier cas. On évite ainsi d’accorder trop de poids à des mots très fréquents, mais parfois peu intéressants sémantiquement, comme des mots de liaison (par exemple et, ou, car). On applique ainsi la PPMI à chaque valeur de la matrice pour obtenir les vecteurs PPMI.
De grands corpus documentaires pour apprendre les plongements lexicaux
Pour obtenir des vecteurs PPMI performants, il est préférable de disposer de corpus textuels volumineux. En effet, dans ces corpus, le vocabulaire est plus grand donc l’espace de description de départ (la matrice de co-occurrences) plus détaillé. Par ailleurs, le volume de co-occurrences est plus élevé et permet donc aux algorithmes de travailler sur une estimation plus fine de la probabilité de co-occurrences des mots. Dans le cas de l’article de Bolukbasi et ses collègues, les auteur·rices considèrent en particulier un corpus anglais de Google news d’environ 100 milliards de mots, et une extraction d’une partie du web issue de Common Crawl avec environ 42 milliards de mots. Ces corpus sont donc issus de l’agrégation de nombreux documents anglais produits par des humain·es, et les plongements lexicaux qui sont appris sur ces corpus par les algorithmes sont ainsi le reflet de l’usage qui a été fait du vocabulaire par ces humain·es.
Les vecteurs sont appelés plongements lexicaux
On parle de méthodes d’apprentissage de plongements lexicaux pour toutes les approches qui cherchent à capturer la sémantique du vocabulaire en utilisant les co-occurrences [3, 4, 5], comme dans le cas de la PPMI. En effet, il s’agit de plonger les mots d’un lexique dans un espace de représentation de sorte que la distance entre les représentations vectorielles des mots dans cet espace illustre leur distance sémantique. On parle également de plongements de mots. Dans les paragraphes suivants, nous détaillons l’utilité de ces plongements pour résoudre deux tâches difficile : la similarité et l’analogie.
Utiliser les plongements lexicaux pour résoudre des tâches sémantiques
Résoudre la tâche d’analogie avec les vecteurs
Les vecteurs PPMI sont par exemple très efficaces sur la tâche d’analogie [6], qui consiste à trouver C dans l’analogie A est à B ce que C est à D. Ainsi par exemple, si l’on considère de tels vecteurs pour représenter le vocabulaire, il est possible de modéliser l’analogie comme des opérations algébriques sur ces vecteurs : on espère que  [3, 7].
[3, 7].
Par exemple, on peut imaginer l’analogie représentée par le concept de capitale : Paris est à la France ce que Varsovie est à la Pologne. Alors, on espère que le vecteur qui est obtenu par les opérations  est très proche du vecteur qui représente Varsovie. Dans la Figure 1 ci-dessous, on illustre l’analogie dans un espace en deux dimensions pour simplifier l’exemple. À gauche, on observe les vecteurs qui représentent Paris (noir), France (vert), Pologne (rouge). À droite, on observe l’opération
est très proche du vecteur qui représente Varsovie. Dans la Figure 1 ci-dessous, on illustre l’analogie dans un espace en deux dimensions pour simplifier l’exemple. À gauche, on observe les vecteurs qui représentent Paris (noir), France (vert), Pologne (rouge). À droite, on observe l’opération  et on constate que le résultat est proche de
et on constate que le résultat est proche de  .
.
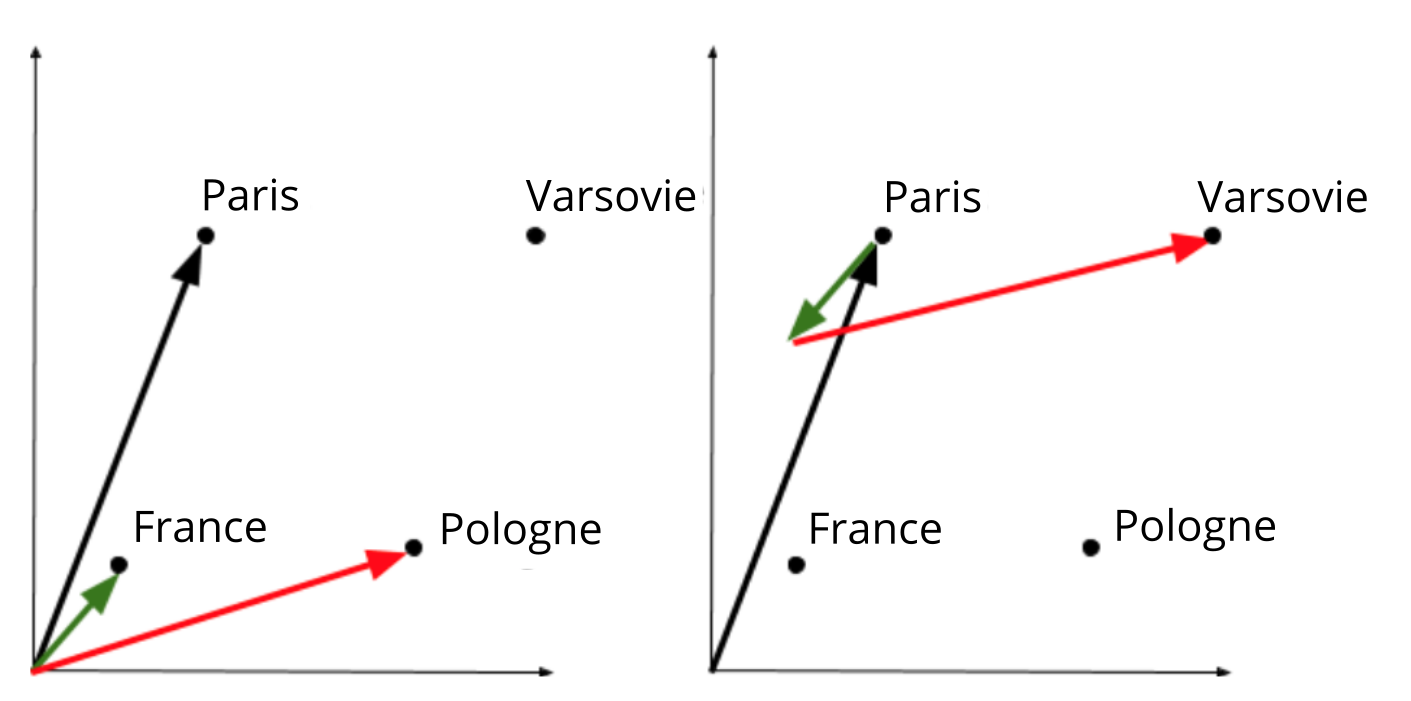
Ce que ce genre d’expérimentation nous montre, c’est que ces vecteurs semblent capables d’encoder, au moins en partie, le sens des mots, ou en tout cas l’utilisation qui en est faite dans le corpus.
Similarité sémantique et similarité entre vecteurs
Les méthodes de plongements lexicaux basées sur les co-occurrences dans de grands corpus de données textuelles permettent d’obtenir des vecteurs également très efficaces pour résoudre la tâche de similarité. Dans cette tâche, on propose paires de mots à des humain·es. Puis, pour chaque paire, on leur demande d’évaluer la similarité des deux mots sur une échelle de 0 à 9. Chaque paire est ensuite associée à la moyenne des scores de similarité donnés par les humain·es, ce qui aboutit au vecteur  , de taille , des similarités humaines.
, de taille , des similarités humaines.
En utilisant les vecteurs obtenus par des approches similaires à la méthode PPMI, l’approche usuelle consiste à calculer numériquement un vecteur de similarités, noté  , en utilisant la distance cosinus (Figure 2) entre les vecteurs qui représentent les paires de mots. La tâche de similarité est correctement résolue lorsque ce vecteur est proche du vecteur , c’est-à-dire quand les similarités sur les vecteurs donnent des résultats cohérents avec ceux des humain·es.
, en utilisant la distance cosinus (Figure 2) entre les vecteurs qui représentent les paires de mots. La tâche de similarité est correctement résolue lorsque ce vecteur est proche du vecteur , c’est-à-dire quand les similarités sur les vecteurs donnent des résultats cohérents avec ceux des humain·es.
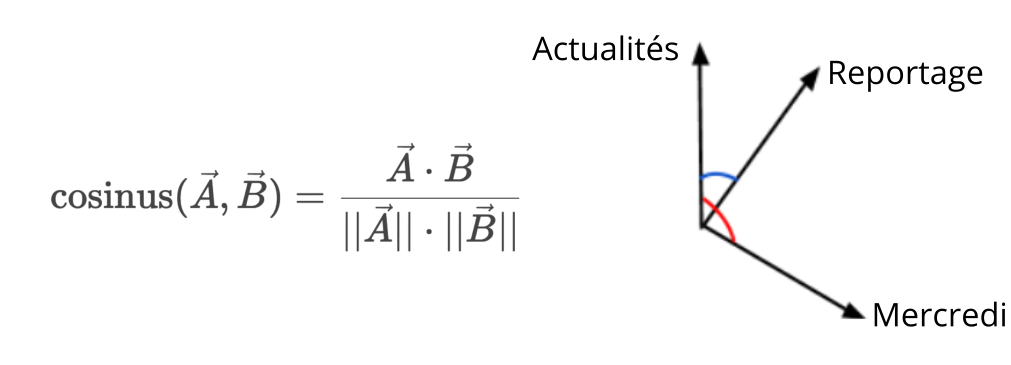
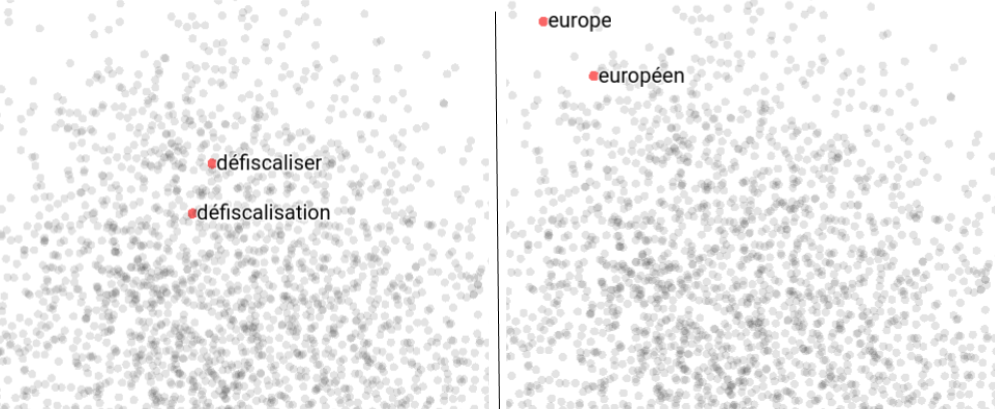
Dans la Figure 2, où l’on considère un espace à deux dimensions pour illustrer la similarité sur les vecteurs, le cosinus de l’angle entre les vecteurs de reportage et celui d’actualités est plus élevée (bleu) que celui de l’angle entre les vecteurs de actualités et mercredi (orange), indiquant une plus grande similarité sémantique entre les mots actualités et reportage dans l’espace appris. On espère que cette similarité calculée est proche de celle donnée par les humain·es. Pour obtenir le vecteur des similarités calculées, on applique ainsi le cosinus aux paires de mots étudiés. On calcule ensuite la corrélation entre , le vecteur de similarités humaines, et , le vecteur de similarités calculées pour évaluer la capacité des vecteurs appris à encoder le sens du vocabulaire et les relations sémantiques (par exemple la synonymie ou l’hyperonymie [*]), entre les mots de ce vocabulaire [7].
Le biais de genre
Caractériser le stéréotype et biais de genre dans les plongements lexicaux
Bolukbasi et ses collègues étudient la façon dont les plongements lexicaux appris par les algorithmes sur ces corpus reproduisent des stéréotypes de genre. Pour ceci, ils définissent deux catégories de mots : les mots genrés, associés à un genre par définition, et le reste des mots qui sont définis comme neutres. Par exemple, le mot frère est par définition associé au genre masculin. Il serait donc normal par exemple de constater que les vecteurs appris par un système informatique trouvent une similarité plus forte entre frère et homme, qu’entre frère et femme. En revanche, les auteur·rices considèrent qu’il y a un stéréotype, ou un biais, lorsqu’un mot dit neutre au sens de leur catégorisation est nettement plus similaire à un genre qu’à l’autre.
Pour évaluer l’existence de tels stéréotypes, les auteur·rices de la publication proposent deux approches : la première considère l’étude des mots qui décrivent des métiers, la seconde s’interroge sur les analogies qui sont produites par les systèmes d’apprentissage automatique.
Dans la première expérimentation, les auteur·rices utilisent une liste de 327 métiers et considèrent parmi ces métiers ceux dont les vecteurs sont les plus proches des vecteurs  (le pronom il en français), ou
(le pronom il en français), ou  (le pronom elle). Iels choisissent les vecteurs appris sur les corpus Google news avec Word2Vec, une approche classique d’apprentissage de plongements lexicaux [3]. Par exemple, les cinq métiers de la liste qui sont les plus similaires à (il) sont dans l’ordre
(le pronom elle). Iels choisissent les vecteurs appris sur les corpus Google news avec Word2Vec, une approche classique d’apprentissage de plongements lexicaux [3]. Par exemple, les cinq métiers de la liste qui sont les plus similaires à (il) sont dans l’ordre  (maître),
(maître),  (skipper),
(skipper),  (protégé),
(protégé),  (philosophe),
(philosophe),  (capitaine) ; les cinq mots les plus proche de (elle) sont
(capitaine) ; les cinq mots les plus proche de (elle) sont  (ménager⋅e),
(ménager⋅e),  (infirmier⋅e),
(infirmier⋅e),  (réceptionniste),
(réceptionniste),  (bibliothécaire),
(bibliothécaire),  (mondain⋅e). Pour les 327 métiers, dix évaluateur·rices humain·es ont noté de 0 à 10 si ces métiers étaient selon elleux plus attachés à un genre qu’à un autre. Les auteur·rices de la publication montrent qu’iels obtiennent une corrélation entre ces notes humaines et entre les scores numérique de similarité entre les métiers et
(mondain⋅e). Pour les 327 métiers, dix évaluateur·rices humain·es ont noté de 0 à 10 si ces métiers étaient selon elleux plus attachés à un genre qu’à un autre. Les auteur·rices de la publication montrent qu’iels obtiennent une corrélation entre ces notes humaines et entre les scores numérique de similarité entre les métiers et  ou
ou  . Iels font ainsi l’hypothèse que les plongements lexicaux reflètent les stéréotypes humains.
. Iels font ainsi l’hypothèse que les plongements lexicaux reflètent les stéréotypes humains.
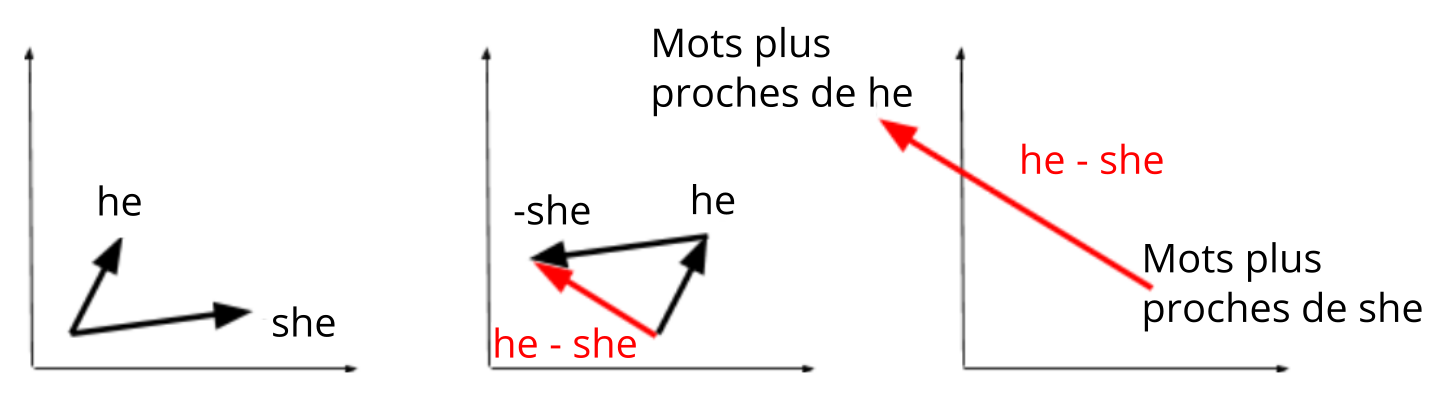
Dans la seconde expérimentation, les auteur·rices cherchent à mettre en avant, parmi les analogies produites algébriquement par les systèmes d’apprentissage automatiques, celles qui sont stéréotypées. Par exemple, la couture est pour elle ce que la menuiserie est pour il est une de ces analogies. En revanche, sœur est pour elle ce que frère est pour il est une analogie qui ne contient pas de stéréotype de genre. D’après l’équation décrivant l’analogie ci-dessus, on sait que chercher des analogies telles que x is to she what y is to he (x est à elle ce que y est à il) est décrite comme  et peut ainsi être réécrite en
et peut ainsi être réécrite en  . Les auteur·rices calculent donc la similarité cosinus entre le vecteur obtenu via
. Les auteur·rices calculent donc la similarité cosinus entre le vecteur obtenu via  et pour toute paire de mots
et pour toute paire de mots  le vecteur
le vecteur  . Iels ordonnent ensuite toutes les paires de mots dans l’ordre décroissant de cette similarité, faisant apparaître ainsi en premier les analogies les plus nettes. Cela permet de découvrir un grand nombre d’analogies stéréotypées avec des couples
. Iels ordonnent ensuite toutes les paires de mots dans l’ordre décroissant de cette similarité, faisant apparaître ainsi en premier les analogies les plus nettes. Cela permet de découvrir un grand nombre d’analogies stéréotypées avec des couples  pour
pour  comme
comme  (designer·euse d’intérieur, architecte),
(designer·euse d’intérieur, architecte),  (infirmi·er·ère, chirurgien·enne),
(infirmi·er·ère, chirurgien·enne),  (ménag·er·ère, commerçant·e). Ainsi, selon la représentation apprise par le modèle, être chirurgien pour un homme équivaudrait à être infirmière pour une femme.
(ménag·er·ère, commerçant·e). Ainsi, selon la représentation apprise par le modèle, être chirurgien pour un homme équivaudrait à être infirmière pour une femme.
Calculer la dimension du genre
Ainsi, les auteur·rices mettent en lumière au sein de l’espace appris par les algorithmes une dimension associée au genre. Par exemple, dans la Figure 3, on imagine un espace en deux dimensions. Au sein de cet espace, on calcule le vecteur , ce qui crée en quelque sorte une nouvelle dimension, avec en haut à gauche de notre plan, en suivant la direction de la flèche rouge, des mots stéréotypés masculins ou par définition masculins, et en bas à droite les mots stéréotypés féminins.
Conséquences du biais sur les algorithmes utilisés dans les applications du quotidien
Les plongements lexicaux sont utilisés pour de nombreuses applications, et donc, des résultats ainsi biaisés peuvent théoriquement propager le stéréotype au-delà des données initiales [**]. Par exemple, on peut imaginer qu’un système de traduction basé sur ce type de plongements génère des contenus plus stéréotypés ou qu’un système de dialogue réponde avec des propos stéréotypés. Un exemple parlant est celui du chatbot de Microsoft ayant tenu des propos racistes dûs au corpus sur lequel il a été appris [8]. Ce genre de préoccupations est au coeur d’un certain nombre de problématiques de recherche sur des algorithmes équitables (fair en anglais). L’objectif de travaux comme ceux que nous évoquons est d’éviter toute discrimination au sein des algorithmes, comme par exemple dans le cadre de COMPAS, algorithme utilisé par le système judiciaire de certains états des Etats-Unis [9], pour prédire les chances de récidives des criminel⋅le⋅s (biais ethniques et religieux dans ce cas [10]). Le biais de genre fait également l’objet de recherches en cours en utilisant de gros corpus médias temporels pour évaluer leur évolution [11].
Debiasing : supprimer le biais de genre dans les plongements
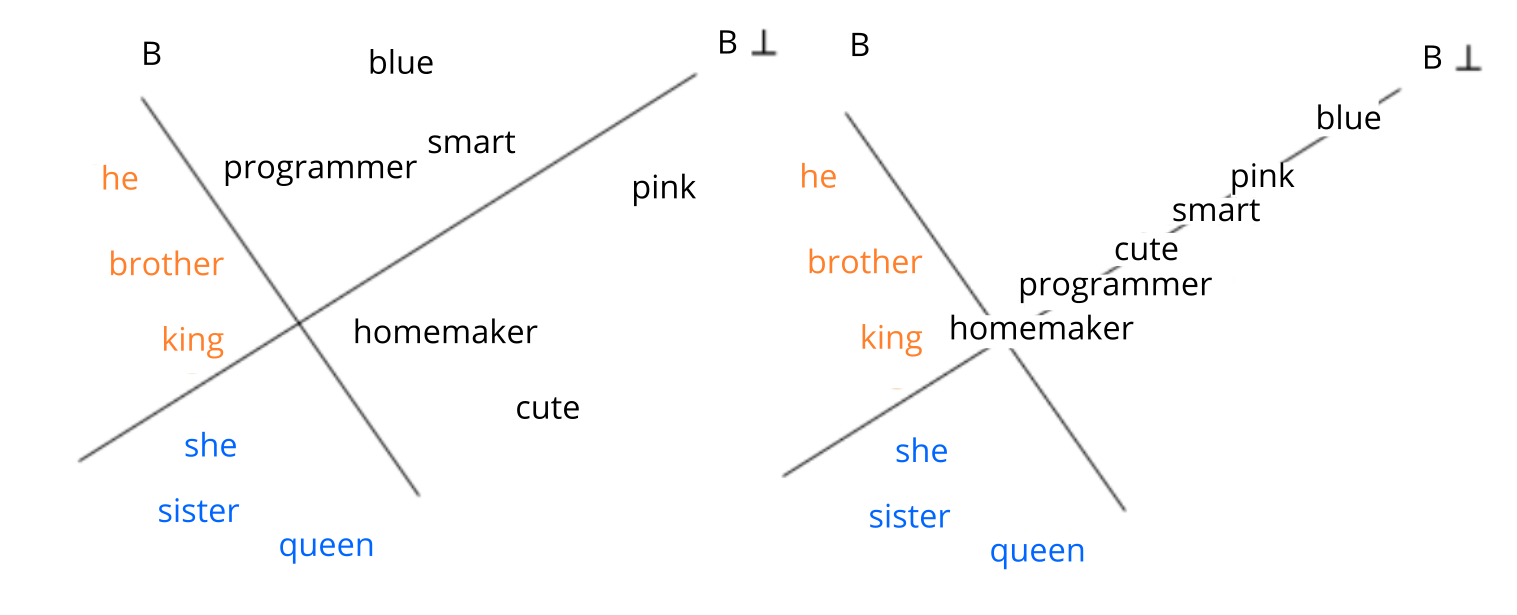
L’idée principale pour gommer les stéréotypes encodés dans les plongements, c’est de faire en sorte que les mots définis comme neutres soient équidistants des mots genrés par définition. Les auteur·rices de la publication définissent ainsi trois ensembles, celui des mots par définition masculins, celui des mots par définition féminins, et celui des mots neutres. À partir des deux ensembles genrés, les auteur·rices définissent la dimension du genre  dans l’espace appris. Ainsi, comme le montre la Figure 4 ci-dessous, on dispose des deux ensembles de mots genrés orange et bleu et d’un ensemble de mots neutres en noir. Le but étant que les mots neutres soient équidistants des centres des ensembles oranges et bleus, on projette donc les mots noirs le long du vecteur orthogonal à comme à droite.
dans l’espace appris. Ainsi, comme le montre la Figure 4 ci-dessous, on dispose des deux ensembles de mots genrés orange et bleu et d’un ensemble de mots neutres en noir. Le but étant que les mots neutres soient équidistants des centres des ensembles oranges et bleus, on projette donc les mots noirs le long du vecteur orthogonal à comme à droite.
Le debiasing est-il efficace ?
La méthode présentée ci-dessus a le mérite d’adresser de manière claire le problème des biais présents dans les espaces de représentation appris. Néanmoins, le débiaisage par cette méthode semble insuffisant comme démontré dans un article écrit par Hila Gonen et Yoav Goldberg [12]. En effet, la méthode proposée suppose qu’il n’y a pas de biais de genre si chaque mot neutre du vocabulaire se trouve à égale distance de toutes les paires explicitement genrées. Ainsi, le biais associé à un mot neutre n’est défini que par rapport aux mots genrés, sans tenir compte du reste du vocabulaire. Pourtant, Hila Gonen et Yoav Goldberg observent dans leur article que les mots neutres pour lesquels on constate un biais (par exemple plus proche de il, ou de elle sur la dimension du genre) semblent regroupés entre eux selon le genre du biais. Comme cas d’illustration, la représentation de infirmier·ère une fois débiaisé sera aussi proche de il que de elle. Par contre, elle restera beaucoup plus proche de mots comme réceptionniste, soignant·e ou enseignant.e que de mots tels que garagiste, guerrier·ère ou fermier·ère. Ces résultats semblent refléter le stéréotype de genre associé à ces métiers. Cette disposition du voisinage ne semble pourtant imputable qu’au biais de genre persistant dans les représentations partiellement débiaisées par la méthode de Bolukbasi et ses collègues.
La présence de biais liés au genre, à la religion ou à la couleur de peau dans les représentations sémantiques s’avère être un problème pour de nombreuses applications comme nous l’avons déjà décrit. Néanmoins, étudier ce biais constitue un outil intéressant d’analyse des stéréotypes présents dans notre société, et offre des perspectives d’analyse systématique à grande échelle permettant de complémenter les approches qualitatives telle que l’analyse manuelle de texte. En suivant cette idée, Nikhil Garg et ses collègues [13] ont proposé une approche pour quantifier les stéréotypes et leur évolution aux États-unis au cours des XXe et du XXIe siècle en utilisant des corpus dans lesquels la date de parution des documents est connue. De manière intéressante, les biais observés sont cohérents avec les études préalables faites en sociologie quantitative, par exemple la répartition des emplois par genre, mais également avec les stéréotypes déjà mis en lumière par les approches classiques. Le Tableau 1 ci-dessous, reproduit de l’article de Garg et ses collègues, montre par exemple les adjectifs les plus associés au genre féminin au cours des décennies 1910, 1950, 1990, ce qui permet d’observer la persistance des stéréotypes de genre.
| 1910 | 1950 | 1990 |
| Charming (charmante) Placid (placide) Delicate (delicate) Passionate (passionnée) Sweet (douce) Dreamy (rêveuse) Indulgent (indulgente) Playful (espiègle) Mellow (douce) Sentimental (sentimentale) | Delicate (delicate) Sweet (douce) Charming (charmante) Transparent (transparente) Placid (placide) Childish (enfantine) Soft (douce) Colorless (incolore) Tasteless (insipide) Agreeable (agréable) | Maternal (maternelle) Morbid (morbide) Artificial (artificielle) Physical (sensuelle) Caring (attentionnée) Emotional (sentimentale) Protective (protectrice) Attractive (séduisante) Soft (douce) Tidy (soignée) |
Garg et ses collègues proposent également de quantifier l’impact d’évènements historiques sur la construction et l’évolution des stéréotypes. Ces chercheur·ses constatent un net changement dans la représentation des stéréotypes féminins correspondant aux mouvements féministes au cours des décennies 1960 et 1970. Iels observent également l’influence des différentes vagues de migrations asiatiques (1960, 1980) ou du « Immigration and Nationality Act » de 1965 sur les représentations stéréotypiques des asiatiques.
Conclusion
Ces travaux montrent que les représentations sémantiques apprises par les algorithmes reproduisent des stéréotypes dérivés de large corpus d’apprentissage dont elles sont issues, indépendamment de la date d’écriture ou des types de textes (articles de journaux, Wikipédia, pages web, etc.). À l’inverse, il n’y a aujourd’hui pas d’élément qui permette d’avancer que les algorithmes utilisés amplifient ou créent ces biais. De plus, les méthodes qui identifient ces biais peuvent nous amener à prendre des précautions quant à l’interprétation des résultats. La rigueur d’une telle étude peut en effet être questionnée quant au choix de la tâche d’analogie pour interpréter ce biais. Nissim et ses collègues expliquent que, si le choix de l’analogie permet des effets d’annonce comme L’homme est au programmeur ce que la femme est à la ménagère ou L’homme est au médecin ce que la femme est à l’infirmière, ces analogies sont pourtant obtenues de façon discutable [14]. Par exemple, on observe L’homme est au programmeur ce que la femme est à la programmeuse dès lors que l’on considère tout le vocabulaire des documents, et pas seulement les 50 000 mots les plus fréquents. Le reste de l’approche de Bolukbasi et ses collègues n’est pas remis en cause par ces travaux, mais le titre et les effets d’annonces peuvent avoir tendance à simplifier et caricaturer un problème pourtant complexe et sensible.
En effet, pour débattre efficacement et déterminer si nous devons viser la suppression du biais ou plutôt la transparence et la sensibilisation [15], il est crucial d’avoir une totale transparence sur la démarche scientifique et les choix subjectifs mis en œuvre. Ainsi, si les grands corpus textuels et les plongements lexicaux offrent une nouvelle manière d’analyser les stéréotypes dans nos sociétés, ces biais soulèvent nombre d’inquiétudes tant l’utilisation de ces plongements est omniprésente — bien qu’invisible — dans notre quotidien. À lui seul, le moteur de recommandation de Youtube, en partie basé sur ce type de représentation [16], avec ces 6,9 milliards de requêtes par jour (80 000 requêtes chaque seconde) légitime ces inquiétudes.
[*] Un terme a est l’hyperonyme d’un terme b si b appartient à la catégorie nommée par a (i.e. si b est un type de a). Par exemple, animal est hyperonyme de poisson qui est lui-même hyperonyme de saumon.
[**] Cas d’exemples des risques envisageables liés à la présence de stéréotypes du genre dans les représentations vectorielles des mots pour des cas d’usage réel.
[1] Firth J.R., « A synopsis of linguistic theory 1930-1955 ». Studies in Linguistic Analysis, 1957. [Livre de science]
[2] Levy O. & Goldberg Y., Neural word embedding as implicit matrix factorization. NIPS Proceedings β, 2014. [Publication scientifique]
[3] Mikolov T., et al., Efficient Estimation of Word Representations in Vector Space. arXiv, version 3, 2018. [Prépublication, article non relu par les pairs]
[4] Sennrich R., et al., Neural Machine Translation of Rare Words with Subword Units. arXiv, version 5, 2015. [Prépublication, article non relu par les pairs]
[5] GloVe: Global Vectors for Word Representation. Pennington J., et al., 2014. [Page de présentation de l’algorithme]
[6] Levy O., et al., Improving Distributional Similarity with Lessons Learned from Word Embeddings. Transactions of the Association for Computational Linguistics, 2015. [Publication scientifique]
[7] Schnabel T., et al., Evaluation methods for unsupervised word embeddings, Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015. [Publication scientifique]
[8] Twitter taught Microsoft’s AI chatbot to be a racist asshole in less than a day. The Verge, 2016. [Article de presse]
[9] Pour prédire la récidive, l’intérêt limité des algorithmes. Sciences et avenir, 2018. [Article de presse]
[10] Wang H., et al., An Empirical Study on Learning Fairness Metrics for COMPAS Data with Human Supervision. NeurIPS, 2019. [Publication scientifique]
[11] L’Agence Nationale de la Recherche accorde un financement au CARISM. Université Paris II Panthéon-ASSAS. [Communiqué de presse]
[12] Gonen H. & Goldberg Y., Lipstick on a Pig: Debiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them. arXiv version 2, 2019. [Prépublication, article non relu par les pairs]
[13] Garg N., et al., Word Embeddings Quantify 100 Years of Gender and Ethnic Stereotypes. PNAS, 2018. DOI : 10.1073/pnas.1720347115. [Publication scientifique]
[14] Nissim M., et al., Fair is Better than Sensational:Man is to Doctor as Woman is to Doctor. arXiv version 2, 2019. [Prépublication, article non relu par les pairs]
[15] Caliskan A. et al., Semantics derived automatically from language corpora contain human-like biases. Science, 2017. DOI : 10.1126/science.aal4230. [Publication scientifique]
[16] Covington P., et al., Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems, 2016. DOI : 10.1145/2959100.2959190. [Publication scientifique]
Publié le 21/09/2020
Victor Connes et Nicolas Dugué/Papier-Mâché/CC BY-NC-SA 4.0 2020Texte et images, à l’exception des images soumises à droits d’auteurs différents : voir au cas par cas en légende.