Chargement de l'article...
Écriture : Thibault Durand
Relecture scientifique : Jennifer Renoux
Relecture de forme : Geoffrey Pruvost et Pauline Colinet
Temps de lecture : environ 8 minutes.
Thématiques : Intelligence artificielle (Informatique)
Publication originale : Goodfellow I., et al., Generative Adversial Networks. NIPS Proceedings β, 2014.
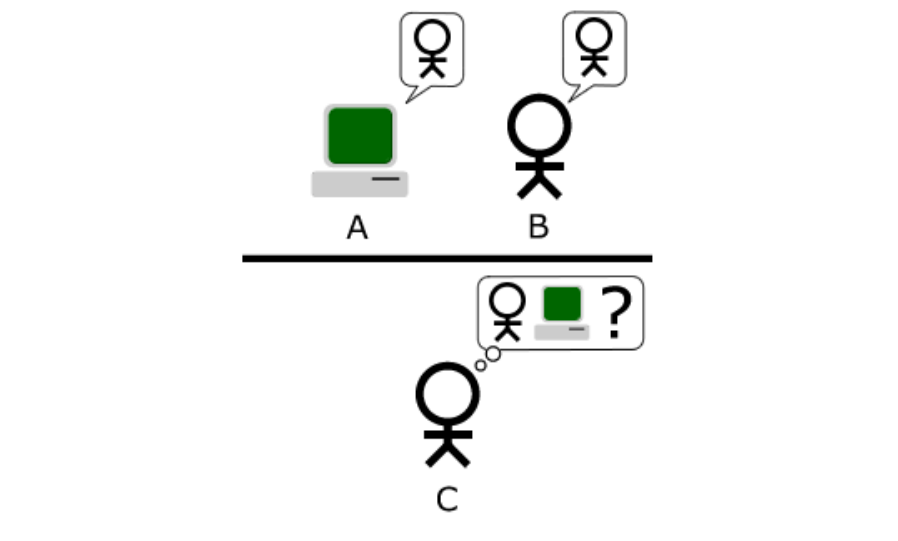
« Une machine peut-elle penser ? » C’est pour répondre à cette question qu’Alan Turing proposa, dans les années 50, son test d’imitation. L’expérience consiste à mettre un être humain en confrontation verbale avec un ordinateur et un autre être humain. Si la personne qui engage les conversations n’est pas capable de dire lequel de ses interlocuteurs est un ordinateur, alors le test est réussi. Aujourd’hui, et pas seulement dans le domaine de la communication verbale, les machines trompent souvent les humains, certes, mais aussi d’autres machines ! Ce procédé est utilisé dans une méthode d’apprentissage fascinante : les réseaux de neurones générateurs adverses.
Mais c’est quoi un réseau de neurones au juste ?
Depuis plusieurs années, on entend parler de réseaux de neurones partout. En médecine par exemple, où des réseaux de neurones sont capables de poser un diagnostic à partir du profil du patient. Dans le même domaine, des réseaux de neurones localisent des cancers sur une image noir et blanc, et ce plus précisément et rapidement que les meilleurs médecins ! Mais c’est quoi un réseau de neurones ?
Peu importe le domaine d’application, retenons qu’un réseau de neurones informatique est une machine à prédire des choses. On peut le voir comme une boîte noire, plus ou moins compliquée à l’intérieur, qui mange quelque chose en entrée, et qui donne une prédiction en sortie. Entre les deux, cette boîte noire fait tout un tas de calculs à partir des données en entrée, et ce pour avoir la meilleure prédiction possible.
Prenons un exemple simple. Imaginons que nous voulions prédire la vitesse de course d’une personne en fonction de sa taille et de son âge. On va donc donner au réseau de neurones ces deux informations, à savoir l’âge et la taille. À partir de ces informations, une multitude de calculs sont réalisés par le réseau, lui permettant de donner en sortie l’information que l’on veut prédire : la vitesse de course de la personne.
Puisque très inspirés de la biologie, on constate une forte similitude entre ces réseaux neuronaux informatiques et nos réseaux neuronaux humains.
Cependant, pour effectuer une telle tâche, un être humain sera d’autant plus juste dans sa prédiction qu’il connaîtra le sujet, c’est-à-dire qu’il aura eu de l’expérience dans la course à pied. Ainsi, un entraîneur d’athlétisme aura de meilleurs prédictions de la vitesse à partir de l’âge et de la taille qu’une personne sans expérience. Mais alors, comment le réseau de neurones informatique parvient, à la manière d’un réseau de neurones biologiques, à s’entraîner pour obtenir de bonnes prédictions ? Par « apprentissage » !
Et oui, la comparaison avec le réseau de neurones biologique continue, puisque le réseau de neurones informatique apprend lui aussi en fonction des expériences et des exemples rencontrés : il ajuste tous ses calculs internes. Ainsi, le réseau de neurones informatique, avant utilisation, doit s’entraîner sur des centaines, des milliers voire parfois des millions d’exemples. Reprenons l’exemple de la vitesse de course d’un individu prédite à partir de son âge et de sa taille.
Pour entraîner le réseau, son concepteur utilise dans un premier temps un certain nombre de données exemples pour ajuster les paramètres. Le réseau commence l’entraînement avec le premier exemple, imaginons, un jeune homme de 28 ans mesurant 1 m 80. Pour cette première donnée d’entraînement , on connaît le temps au 100 m : 12,5 secondes. Sont ainsi transmises au réseau les informations concernant l’âge du coureur, sa taille ainsi que son temps au 100 m. À partir des deux premières informations (taille et âge), le réseau va prédire le temps de course à partir de calculs de base et comparer sa prédiction au temps véritable mesuré pour cet exemple. S’agissant du premier exemple, la prédiction risque de tomber à côté de la réalité, comme se tromperait un individu non spécialisé en course à pied. Supposons que le réseau prédise 18 secondes. Comme le réseau connaît le vrai temps de course, il est ainsi capable de mesurer son erreur qui est de 5,5 secondes pour cet exemple. En fonction de la valeur de cette erreur, il modifie et ajuste alors ses paramètres internes pour compenser cette erreur, et ne plus faire d’erreurs aussi grossières par la suite. Ainsi, le deuxième exemple présenté au réseau aura probablement une erreur plus faible, et ainsi de suite.
Une fois que l’on constate que le réseau ne parvient plus à réduire significativement les niveaux d’erreur sur les exemples présentés, on considère le réseau « entraîné ». Le terme significativement signifie que l’on a préalablement fixé un seuil à partir duquel les erreurs sont en moyenne suffisamment faibles pour que l’on juge le réseau entraîné. En effet, il y aura toujours une erreur, plus ou moins grande, et c’est la nature de l’application qui nous fait définir ce seuil. Pour la course à pied, cela n’est pas grave de se tromper d’une seconde. En revanche, pour des applications délicates telles que la détection automatique de zones cancéreuses dans le but de soigner ces zones par rayonnements, une erreur d’un centimètre n’est pas acceptable.
Gardons en tête que les réseaux de neurones sont souvent très complexes à l’intérieur, d’où le terme de boîtes noires, puisqu’il est difficile de comprendre intuitivement et d’interpréter comment le réseau prédit la sortie. Dans ce contexte, on peut imaginer ajouter d’autres informations en entrée, par exemple le sexe du coureur, ou sa masse. Ainsi, le réseau de neurone prendra certainement plus de temps à optimiser ses paramètres, mais ses prédictions seront probablement de meilleure qualité.
Des réseaux, d’accord ! Mais générateurs et adverses, kesaco ?
Les réseaux de neurones générateurs adverses — GAN pour la suite — sont, on l’aura deviné, un cas particulier des réseaux de neurones. Ces réseaux, développés par Ian GoodFellow dans la publication discutée ici, sont le rêve d’Alan Turing ! L’idée est de juxtaposer deux réseaux de neurones, c’est-à-dire deux boîtes noires, chacune capable de prédire quelque chose, de manière à créer une architecture susceptible imiter n’importe quel type de données.
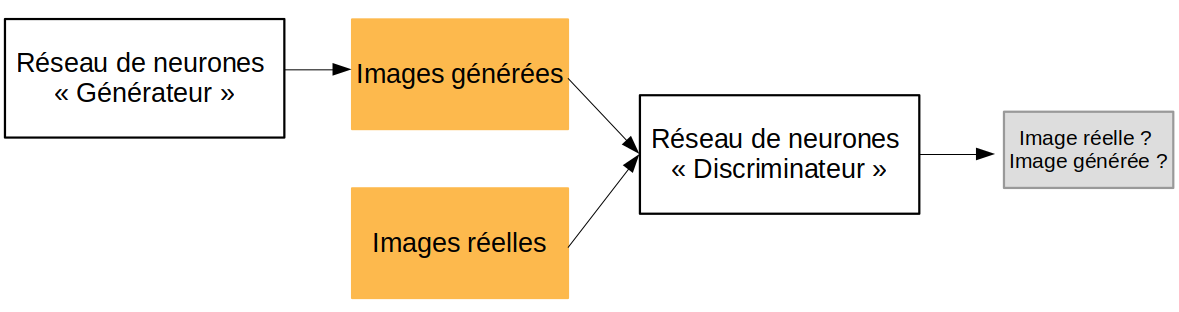
Décrivons dans un premier temps ce que fait chacune des deux boîtes noires (cadres noirs), illustrées Figure 1. La première, qui correspond au premier réseau est appelée générateur. Il prend en entrée quelques chiffres aléatoires et génère en sortie un exemple de donnée qui y ressemble. Il s’agit, pour le générateur, de « prédire » une structure de données cohérentes à partir d’une base de données réelles. On parle alors de « création » dans le sens où le réseau doit inventer des données. Son but est en effet de tromper le deuxième réseau, c’est-à-dire de faire passer ses créations, ni vu ni connu, parmi une multitude de données réelles. Ce deuxième réseau, le discriminateur, ou réseau adverse, prend des données réelles et des données générées par le générateur. Il doit ensuite essayer de prédire s’il s’agit effectivement de données créés de toute pièce par le générateur, ou si elles sont réelles. Il doit démêler le vrai du faux, et ne pas se faire berner. Prenons un exemple. Dans la génération d’images, l’objectif est de construire une fausse image. Il faut donc attribuer à chaque pixel une valeur de gris entre 0 et 255 (0 étant le noir et 255 le blanc) de manière à avoir un rendu visuellement satisfaisant. Dans cet exemple, le générateur prend donc en entrée des valeurs aléatoires de niveau de gris, par exemple 5, 10, 3, 6 et 15, dans cet ordre, et prédit une image entière, c’est-à-dire la valeur de gris de chaque pixel.
Comment cet ensemble de deux réseaux est-il entraîné ? Restons dans la génération d’images avec l’exemple du StyleGan2, un réseau capable de générer des visages ! Dans un premier temps, le générateur comme le discriminateur sont peu performants. Le générateur crée effectivement des visages très grossiers. Tant mieux pour le discriminateur, cela lui permet de s’entraîner à différencier le vrai du faux sur des exemples faciles ! Une fois que le discriminateur différencie facilement les exemples grossiers de la réalité, c’est au tour du générateur de s’améliorer. Son rôle étant de tromper le discriminateur, il va être contraint d’améliorer ses précédentes créations, de les faire ressembler davantage aux données réelles. Les visages sont donc un peu moins grossiers, ce qui biaise le discriminateur qui doit continuer à progresser, et ainsi de suite. Par émulation, les deux réseaux vont ainsi devenir très performants.
L’ironie est que, en répétant ce processus, les deux réseaux arrivent à des niveaux de performances tels que les sens humains ne sont parfois plus capables de savoir si une donnée provient du générateur ou de la base de données réelle ! Il arrive même parfois que le réseau discriminateur devienne meilleur que les sens humains, et perçoive mieux le vrai du faux.
Des applications bluffantes
StyleGan2, basée sur les GAN, génère des visages de personnes qui n’existent pas. Vous pouvez vous amuser sur le site mis à disposition par les auteurs : thispersondoesnotexist.com. Il faut maintenant comprendre que les domaines d’application ne se limitent pas seulement à la génération de visages. Concernant des données audios, l’entreprise Aiva propose un réseau capable de produire des musiques classiques générées à 100 % par un ordinateur grâce à de l’apprentissage automatique ! Restons dans le domaine artistique avec le collectif d’artistes français Obvious qui utilise les GAN comme outils de création artistique. Les GAN génèrent une image fictive à partir d’une sélection d’images choisies. Ils travaillent ensuite « l’œuvre » et l’impriment.
Hors du domaine artistique, il existe d’autres applications comme en sécurité informatique. Dans SSGAN [1] par exemple, les auteurs cachent de l’information au sein d’une image.
Cependant, tout n’est pas rose et les GAN peuvent aussi présenter des risques. Outre les problèmes éthiques soulevés par certaines applications, notamment à des fins marketing (par exemple des publicités ciblées), les GAN permettent aussi la création de faux discours et de fausses images. Ainsi, les deepfake, ces faux discours de personnalités ou de politiques, sont de plus en plus convaincants. On peut, en quelques secondes sur internet, voir Barack Obama avoir des propos qu’il n’a en réalité jamais tenus ! Certains chercheurs travaillent d’ailleurs sur des discriminateurs plus performants, capable de détecter les faux discours des authentiques et donc de battre les générateurs de faux discours.
[1] Shi H., et al., SSGAN: Secure Steganography Based on Generative Adversarial Networks. arXiv, version 4, 2018. [Prépublication, article non relu par les pairs]
Publié le 20/09/2020
 Thibault Durand/Papier-Mâché/CC BY-NC-SA 4.0 2020
Thibault Durand/Papier-Mâché/CC BY-NC-SA 4.0 2020Texte et images, à l’exception des images soumises à droits d’auteurs différents : voir au cas par cas en légende.
Écriture : Thibault Durand
Relecture scientifique : Jennifer Renoux
Relecture de forme : Geoffrey Pruvost
Temps de lecture : environ 11 minutes.
Thématiques : Intelligence artificielle (Informatique)
Publication originale : Goodfellow I., et al., Generative Adversial Networks. NIPS Proceedings β, 2014.
« Une machine peut-elle penser ? » C’est pour répondre à cette question qu’Alan Turing proposa, dans les années 50, son test d’imitation. L’expérience consiste à mettre un être humain en confrontation verbale avec un ordinateur et un autre être humain. Si la personne qui engage les conversations n’est pas capable de dire lequel de ses interlocuteurs est un ordinateur, alors le test est réussi. Aujourd’hui, et pas seulement dans le domaine de la communication verbale, les machines trompent souvent les humains, certes, mais aussi d’autres machines ! Ce procédé est utilisé dans une méthode d’apprentissage fascinante : les réseaux de neurones générateurs adverses.
Mais c’est quoi un réseau de neurones au juste ?
Depuis plusieurs années, les réseaux de neurones sont partout. En médecine par exemple, où des réseaux sont capables de poser un diagnostic à partir du profil du patient. Dans le même domaine, des réseaux localisent des cancers sur une image noire et blanc, et ce plus précisément et rapidement que les meilleurs médecins ! Mais c’est quoi un réseau de neurones, et comment ça fonctionne ?
Peu importe le domaine d’application, retenons qu’un réseau de neurones est une fonction mathématique. Pour rappel, une fonction mathématique c’est une suite d’opérations. Prenons par exemple la fonction linéaire  . Ici,
. Ici,  est un entier positif, l’entrée de notre réseau, alors que
est un entier positif, l’entrée de notre réseau, alors que  et
et  sont les variables de notre fonction, figées et permettant de calculer la sortie
sont les variables de notre fonction, figées et permettant de calculer la sortie  pour n’importe quel entier positif.
pour n’importe quel entier positif.
Comme toute fonction, notre réseau de neurones prend une entrée, effectue une multitude de calculs plus ou moins complexes, et renvoie une sortie. Entre les deux, les opérations mathématiques sont représentées sous forme de couches elles-mêmes constituées d’une multitude de « neurones », les sorties d’une couche étant les entrées de la couche suivante. Un réseau de neurones est une fonction mathématique et les neurones représentent les variables de la fonction, les entrées de la première couches étant les entrées du réseau et les sorties de la dernière couche étant les valeurs à prédire. Puisque très inspirés de la biologie, on constate ainsi une forte similitude entre les réseaux neuronaux humains et les réseaux neuronaux informatiques. La Figure 1 donne un exemple d’architecture très sommaire de réseau à trois couches.
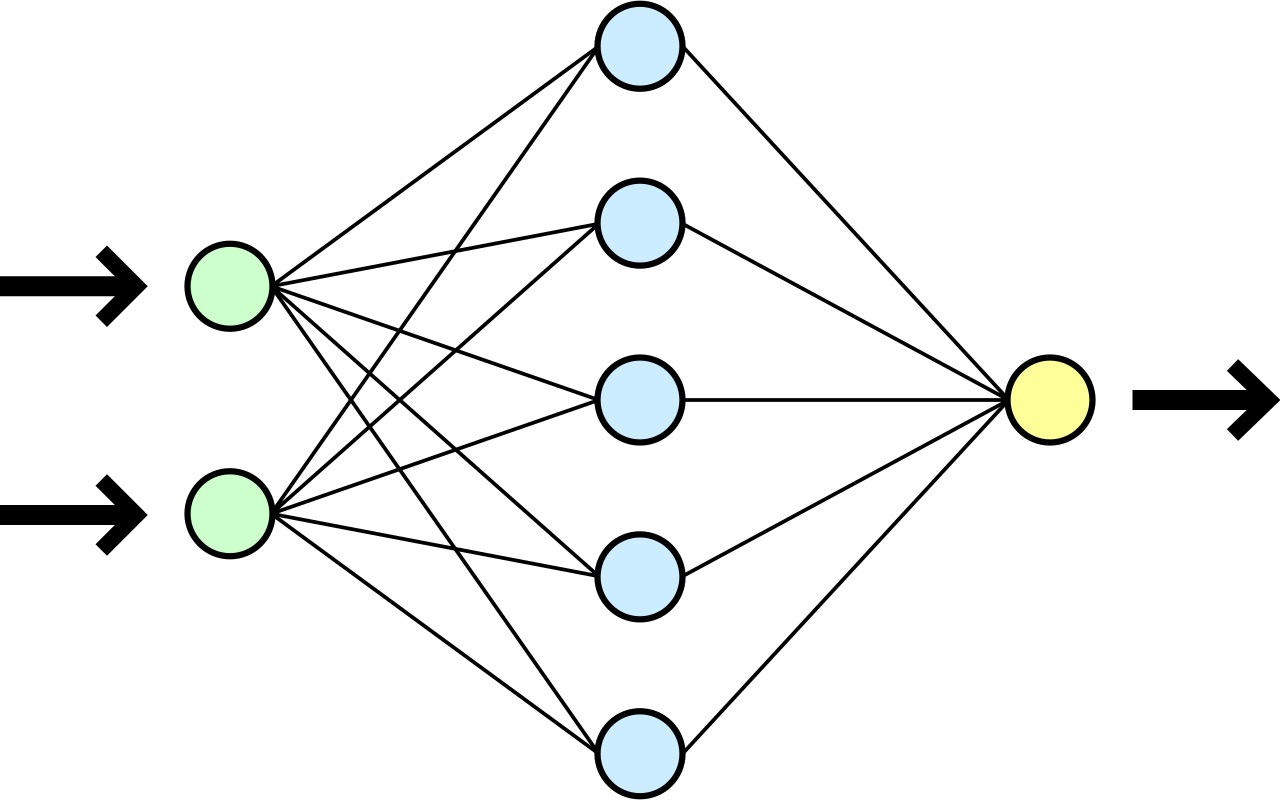
Prenons un exemple simple. Imaginons que nous voulions prédire la vitesse de course d’une personne en fonction de sa taille et de son âge. Prenons le réseau de la Figure 1 pour résoudre un tel problème.
- La première couche est constituée de deux neurones, chacun matérialisant une variable d’entrée (l’âge en années et la taille en centimètres par exemple). Cette première couche correspond donc aux données associées à notre problème. Pour le traitement d’images, il s’agirait par exemple de la valeur et de la position de chaque pixel.
- La seconde couche, appelée couche cachée, constituée de cinq neurones, utilise les deux variables d’entrées et les paramètres internes du réseau pour construire cinq variables intermédiaires. En fonction de la valeur des variables vers lesquelles le réseau aura convergé, c’est-à-dire en fonction de la valeur des et choisis par le réseau, ces variables intermédiaires auront une interprétabilité différente. Ici, avoir cinq variables intermédiaires est un choix arbitraire. On peut d’ailleurs rendre le réseau plus complexe en y mettant plus de cinq neurones intermédiaires (plus large) ou en introduisant plus de couches intermédiaires (plus profond). Par ailleurs, on observe que les deux variables d’entrée sont utilisées dans la définition de chacun des neurones intermédiaires, chaque neurone de la première couche étant en effet relié à la couche intermédiaire. Mathématiquement, en appelant
 et
et  les deux neurones en entrée et
les deux neurones en entrée et  le premier neurone de la couche intermédiaire, alors on peut écrire
le premier neurone de la couche intermédiaire, alors on peut écrire  , avec
, avec  ,
,  ,
,  et
et  des paramètres internes au réseau à ajuster pour bien modéliser le problème. En mettant en cascade ces couches de neurones, on perçoit la puissance de modélisation des réseaux. En pratique, on place derrière chacune de ces opérations linéaires une opération non-linéaire. Un réseau de neurones n’est en fait qu’une multitude de classifieur mis en cascade, et donc cela finit par faire un modèle très puissant.
des paramètres internes au réseau à ajuster pour bien modéliser le problème. En mettant en cascade ces couches de neurones, on perçoit la puissance de modélisation des réseaux. En pratique, on place derrière chacune de ces opérations linéaires une opération non-linéaire. Un réseau de neurones n’est en fait qu’une multitude de classifieur mis en cascade, et donc cela finit par faire un modèle très puissant. - La troisième et dernière couche est ici la couche de sortie du réseau. On constate une seule sortie dans cette architecture.
Bien qu’il semble difficile de prédire la vitesse de sprint en fonction seulement de l’âge et la taille, on peut imaginer augmenter le nombre d’entrées et le nombre de couches intermédiaires afin d’avoir un modèle suffisamment complexe pour prédire assez correctement la vitesse de course. On pourrait par exemple ajouter une variable binaire pour le sexe du coureur ou sa masse en kilogrammes.
Mais alors comment le réseau, qui n’est qu’une fonction mathématique, parvient-il à calculer les probabilités d’un diagnostic ou la position d’un cancer sur une radiographie ? Comment ajuster les paramètres pour estimer au mieux la vitesse sur 100 mètres ? Par « apprentissage » !
Et oui, la comparaison avec le réseau de neurones biologique continue, puisque le réseau de neurones informatique apprend lui aussi en fonction des expériences et des exemples rencontrés, c’est-à-dire qu’il ajuste les paramètres , , et décrits précédemment. Ainsi le réseau, avant utilisation, doit s’entraîner sur des centaines, des milliers voire parfois des millions d’exemples pour ajuster ses paramètres. Reprenons l’exemple du temps de course au 100 mètres, prédit à partir de l’âge et de la taille.
Mathématiquement, le réseau est un modèle appelé  qui prédit
qui prédit  , le temps de course au 100 mètres, en fonction de et , l’âge et la taille, selon
, le temps de course au 100 mètres, en fonction de et , l’âge et la taille, selon  . Plus le modèle dispose de données pertinentes pour le problème, et plus il sera performant.
. Plus le modèle dispose de données pertinentes pour le problème, et plus il sera performant.
Pour entraîner le réseau, on utilise dans un premier temps un certain nombre de données d’apprentissage pour ajuster les paramètres. Le réseau commence l’entraînement avec le premier exemple, imaginons un jeune homme de 28 ans mesurant 1 m 80. Pour cette donnée d’entraînement , on connaît le temps au 100 mètres : 12,5 secondes. Le réseau va ainsi calculer, à partir de  , et
, et  , la sortie . S’agissant du premier exemple, les paramètres ont été initialisés aléatoirement, et la sortie risque de viser à côté de la réalité. Supposons trouver = 18 secondes, le réseau va alors modifier ses paramètres internes pour compenser cette erreur (de +5,5 secondes) dans les paramètres du réseau, et les corriger. On parle de rétro-propagation de l’erreur : il s’agit d’une méthode mathématique pour calculer et corriger l’erreur au niveau de chaque neurone du réseau. Ainsi, le deuxième exemple présenté au réseau aura probablement une erreur plus faible, et ainsi de suite. Une fois que l’on constate des erreurs faibles au niveau de la prédiction, on considère le réseau « entraîné », on peut donc procéder à des tests.
, la sortie . S’agissant du premier exemple, les paramètres ont été initialisés aléatoirement, et la sortie risque de viser à côté de la réalité. Supposons trouver = 18 secondes, le réseau va alors modifier ses paramètres internes pour compenser cette erreur (de +5,5 secondes) dans les paramètres du réseau, et les corriger. On parle de rétro-propagation de l’erreur : il s’agit d’une méthode mathématique pour calculer et corriger l’erreur au niveau de chaque neurone du réseau. Ainsi, le deuxième exemple présenté au réseau aura probablement une erreur plus faible, et ainsi de suite. Une fois que l’on constate des erreurs faibles au niveau de la prédiction, on considère le réseau « entraîné », on peut donc procéder à des tests.
L’idée est d’effectuer les tests sur d’autres données que les données d’entraînement, pour vérifier que le réseau n’a pas appris par cœur les cas d’exemple et qu’il est bien capable de généraliser. Pour ce faire, il faut tester le modèle sur des données inconnues et vérifier que les taux d’erreurs rentrent dans les clous. Une fois que le modèle est validé, on peut l’utiliser. La validation du modèle dépend beaucoup de l’application et des données. Pour un détecteur de cancer par exemple, mieux vaut que le modèle voie des cancers un peu trop souvent, même si parfois ils n’en sont pas (on aura ce qu’on appelle des faux positifs) plutôt que trop peu souvent (on aura des faux négatifs, c’est-à-dire des cancers non vus). Gardons en tête que les réseaux de neurones ont souvent beaucoup plus de paramètres que dans notre exemple, ce qui conduit à de véritables boîtes noires pour lesquelles les couches internes sont difficilement interprétables. À titre indicatif, certains réseaux en traitement d’image ont plusieurs milliards de paramètres !
Des réseaux, d’accord ! Mais générateurs et adverses, kesaco ?
Les réseaux de neurones générateurs adverses — GAN pour la suite — sont, on l’aura deviné, un cas particulier des réseaux de neurones. Ces réseaux, dont l’architecture a été développée par Ian GoodFellow dans la publication discutée ici, sont le rêve d’Alan Turing ! L’idée est de juxtaposer deux réseaux de neurones de manière à créer une architecture capable d’imiter n’importe quel type de données. C’est ce que l’on observe Figure 2.
Décrivons dans un premier temps l’architecture illustrée Figure 2. Le premier réseau, appelé générateur, prend en entrée un bruit aléatoire et génère en sortie un exemple de donnée. Son but est de tromper le deuxième réseau, c’est-à-dire de faire passer ses créations, ni vu ni connu, parmi une multitude de données réelles. Ce deuxième réseau, le discriminateur, ou réseau adverse, prend en entrée parfois des données réelles, parfois des données générées par le générateur. Il doit ensuite prédire s’il s’agit effectivement de données créées de toute pièce par le générateur, ou si elles viennent d’une base de données réelles. Il doit démêler le vrai du faux, et ne pas se faire tromper.
Comment le réseau est-il alors entraîné ? Prenons pour la suite l’exemple du StyleGan2, un réseau capable de générer des visages ! Dans un premier temps, le générateur comme le discriminateur sont peu performants. Le générateur crée effectivement des visages très grossiers. Tant mieux pour le discriminateur, cela lui permet de s’entraîner à différencier le vrai du faux sur des exemples faciles ! Une fois que le discriminateur différencie facilement les exemples grossiers de la réalité, c’est au tour du générateur de s’améliorer. Son rôle étant de tromper le discriminateur, il va être contraint d’améliorer ses précédentes créations, de les faire ressembler davantage aux données réelles. Les visages sont donc un peu moins grossiers, ce qui induit en erreur le discriminateur qui doit continuer à progresser, et ainsi de suite. Par émulation, les deux réseaux vont ainsi devenir très performants.
L’ironie est que, en répétant ce processus et par émulation, les deux réseaux arrivent à des niveaux de performances tels que les sens humains ne sont parfois plus capables de savoir si une donnée provient du générateur ou de la base de données réelle ! Il arrive même parfois que le réseau discriminateur devienne meilleur que les sens humains, et perçoive mieux le vrai du faux.
Des applications bluffantes
Prenons un peu le temps d’observer ce que certains générateurs après apprentissage peuvent donner.
StyleGan2, basée sur les GAN, génère des visages de personnes qui n’existent pas. Vous pouvez vous amuser sur le site mis à disposition par les auteurs : thispersondoesnotexist.com. De même, et concernant des données audios, l’entreprise Aiva propose une solution capable de produire des musiques classiques générées à 100 % par un ordinateur grâce à de l’apprentissage automatique ! Restons dans le domaine artistique avec le collectif d’artistes français Obvious qui utilise les GAN comme outils de création artistique. Les GAN génèrent une image fictive à partir d’une sélection d’images choisies. Ils travaillent ensuite « l’œuvre » et l’impriment.
En dehors du domaine artistique, il existe d’autres applications comme en sécurité informatique. Dans SSGAN [1] par exemple, les auteurs cachent de l’information au sein d’une image.
Cependant, tout n’est pas rose et les GAN peuvent aussi présenter des risques. Outre les problèmes éthiques soulevés par certaines applications, notamment à des fins marketing (par exemple des publicités ciblées), les GAN permettent aussi la création de faux discours et de fausses images. Ainsi, les deepfake, ces faux discours de personnalités ou de politiques, sont de plus en plus convaincants. On peut en quelques secondes sur internet voir Barack Obama avoir des propos qu’il n’a en réalité jamais tenus ! Certains chercheurs travaillent d’ailleurs sur des discriminateurs plus performants, capable de détecter les faux discours des authentiques et donc de battre les générateurs de faux discours.
[1] Shi H., et al., SSGAN: Secure Steganography Based on Generative Adversarial Networks. arXiv, version 4, 2018. [Prépublication, article non relu par les pairs]
Publié le 20/09/2020
Thibault Durand/Papier-Mâché/CC BY-NC-SA 4.0 2020Texte et images, à l’exception des images soumises à droits d’auteurs différents : voir au cas par cas en légende.