Cet article a été traduit depuis le site Oncobites
Écriture (anglais) : Jason Tetro
Traduction : Aurélien Schwob
Relecture scientifique : Eléonore Pérès
Relecture de forme : Jérémy Ferrand
Difficulté :
Temps de lecture : environ 6-7 minutes.
Thématique : Oncologie (Biologie)
Publication originale : Chen L., et al., Pan-Cancer Analysis Reveals the Functional Importance of Protein Lysine Modification in Cancer Development. Frontiers in Genetics, 2018. DOI : 10.3389/fgene.2018.00254
Quelles sont les causes du cancer ? Cette question taraude scientifiques et intellectuels depuis des millénaires [1], mais aucune réponse concrète n’a encore été trouvée. Au IVe siècle avant notre ère, Hippocrate croyait qu’elle résidait dans la présence de bile noire, qui était pour lui l’une des quatre humeurs majeures du corps. Au cours des siècles, d’autres théories ont émergé comme les altérations du système lymphatique (le réseau de transport de la lymphe impliquée notamment dans les défenses immunitaires), l’irritation chronique, les traumatismes ou encore la présence de parasites. Ce n’est que dans les années 1970 que les analyses moléculaires ont découvert la présence de gènes oncogènes, qui favorisent l’apparition d’un cancer, et de gènes suppresseurs de tumeurs, qui limitent le développement d’un cancer. Pourtant, même la découverte de ces deux facteurs ne permet pas de prédire correctement l’apparition d’un cancer chez un individu donné.
Aujourd’hui, une recherche basée sur des preuves moléculaires s’est développée en partie grâce à la capacité de séquencer le génome humain, c’est-à-dire de déterminer l’information (appelée séquence) portée par les gènes. Une inspection plus approfondie de notre information génétique a révélé que le cancer n’est généralement pas dû à une cause unique. Au lieu de cela, une combinaison de différentes altérations du génome — connues sous le nom de mutations — conduit à un point de basculement à partir duquel la cellule devient cancéreuse.
Certains de ces changements sont connus pour avoir un impact plus important que d’autres sur l’apparition du cancer. Collectivement, ils sont connus sous le nom de mutations conductrices (driver mutations en anglais) [2]. Celles-ci peuvent se présenter sous presque toutes les formes. Certaines sont des changements ponctuels dans la séquence génomique, connues sous le nom de mutations ponctuelles (ou SNP pour Single Nucleotide Polymorphism). D’autres sont des réarrangements complexes de grands segments génomiques. Enfin, il y a la duplication ou la suppression accidentelle de segments du génome, appelées variation du nombre de copies d’un gène [3].
Bien que les chercheurs aient progressé vers la compréhension de la cause des cancers, ils ont aussi, par leurs avancées, rendu le paysage plus complexe. Les recherches sur le génome humain ont donné lieu à de vastes bases de données telles que l’Atlas du génome du cancer et le Consortium International sur le Génome du Cancer. Des dizaines de milliers de séquences génomiques humaines sont conservées dans ces dépôts et plus d’un million de mutations différentes ont été enregistrées. Cette quantité de Big Data peut paraître impressionnante, mais sans une analyse rigoureuse, la probabilité de trouver une cause au cancer est une tâche ardue.
En 2018, un groupe de chercheurs chinois a révélé qu’il était à la hauteur de cette tâche en publiant un article fascinant dans Frontiers in Genetics [4]. Ils ont examiné de plus près les mutations conductrices dans l’espoir de trouver un suspect principal. Leurs analyses ont révélé qu’un processus particulier dans la cellule semblait fortement contribuer à l’apparition d’un cancer. Ce sont les modification qui touchent la lysine, un acide aminé particulier qui entre dans la constitution de nos protéines. D’après les résultats, des variations de ces modifications de la lysine pourraient constituer un signe avant-coureur du développement d’un cancer.
La modification de la lysine, comme son nom l’indique, est un processus par lequel une protéine est modifiée par la fixation d’une molécule à l’une des lysines de cette protéine, par un processus appelé liaison covalente. Plusieurs types de modifications covalentes ont été décrites :
- l’ubiquitinylation (aussi appelée ubiquitination) [5], qui peut modifier de nombreux paramètres de la vie de la protéine comme sa durée de vie ou sa localisation dans la cellule ;
- la SUMOylation [6], proche de l’ubiquitination qui permet notamment de modifier la fonction de la protéine au cours d’un stress cellulaire ;
- l’acétylation [7], qui peut permettre à une protéine d’interagir avec d’autre protéines partenaires ;
- la méthylation [8], permettant d’empêcher l’association avec d’autres protéines.
Sachant que la modification de la lysine est un élément clé de la fonction cellulaire normale, les auteurs ont émis l’hypothèse que tout changement dans ce processus dû à une mutation pourrait conduire une cellule vers un cancer. Pour le prouver, ils ont effectué des simulations informatiques complexes (Figure 1). À l’aide des bases de données de l’Atlas du Génome du Cancer et du Consortium International sur le Génome du Cancer, ils avaient plus de 100 000 sites possibles de modification de la lysine sur plus de 13 000 protéines à analyser, tous cancers confondus. Ils avaient aussi plus d’un million de mutations possibles influençant l’apparition d’un cancer à prendre en considération. La tâche n’allait pas être facile, mais ils pensaient que cela en valait la peine.
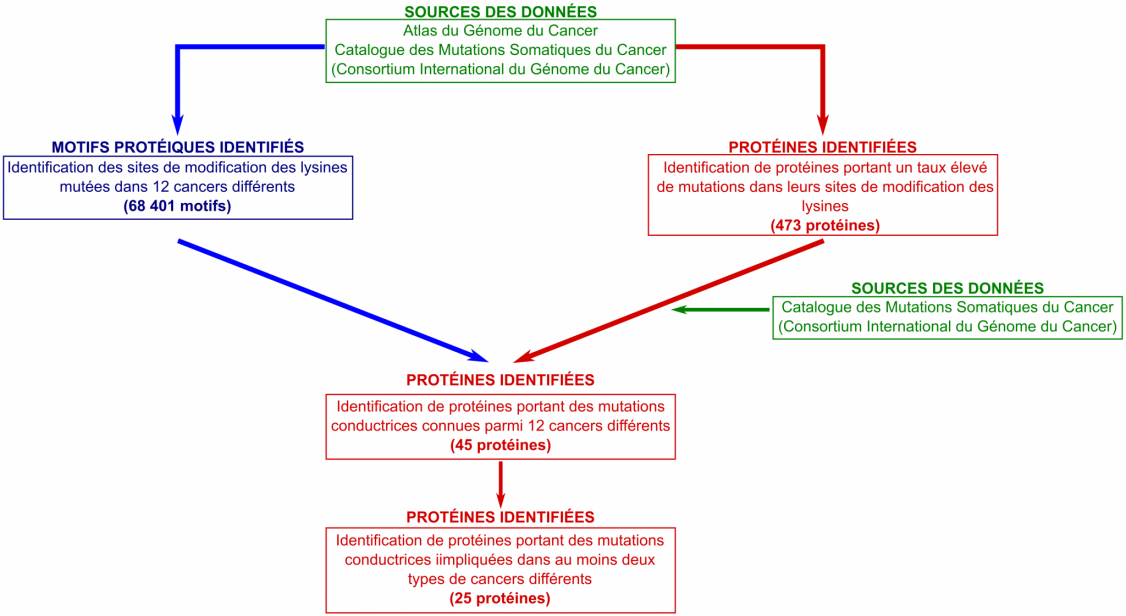
Au cours de la première série d’analyses, l’équipe a tenté de trouver des motifs protéiques permettant la mutation de lysines dans le génome de 12 cancers différents recensés dans les bases de données [*]. Le résultat final a été une réduction d’un tiers du nombre de sites possibles. Ce nombre, 68 401, était encore trop grand pour permettre de rechercher une cause possible, mais cela représentait déjà un gros progrès.
L’étape suivante du processus a consisté à examiner les protéines porteuses de mutations conductrices et qui possèdent un taux élevé de mutations dans leurs sites de modification des lysines. Sur plus de 13 000 protéines candidates possibles, seulement 473 présentaient des taux de mutation plus élevés dans leurs sites de modification des lysines que dans le reste de leur séquence. Pour savoir lesquelles ont contribué aux cancers, l’équipe s’est à nouveau référée au Catalogue des Mutations Somatiques du Cancer pour y trouver quelles protéines étaient porteuses de mutations conductrices. Cette étape a radicalement réduit le nombre à 45 protéines, puis à 25 protéines en ne gardant que les protéines impliquées dans plus d’un type de cancer parmi les 12 étudiés.
Avec un nombre plus gérable à portée de main, l’équipe a effectué la dernière étape de l’exercice. Ils ont essayé de découvrir quels processus cellulaires étaient affectés par ces mutations. Étant donné qu’un cancer est un phénomène dans lequel les cellules ont tendance à proliférer de façon incontrôlable, il n’a pas été surprenant de constater que ces protéines sont principalement impliquées dans le cycle de vie des cellules, y compris la mitose (étape de duplication des cellules où une cellule mère donne deux cellules filles identiques). Peut-être plus important, bon nombre de ces protéines sont également impliquées dans la mort cellulaire programmée, processus crucial dans la destruction des cellules pré-cancéreuses sous l’effet des suppresseurs de tumeurs. Les mutations entraînent ainsi principalement des changements dans la façon dont la cellule vit, se reproduit et meurt.
En rassemblant toutes les informations, l’équipe a conclu que les mutations de la lysine sont des facteurs importants dans l’apparition et la progression d’un cancer à travers un changement dans le cycle cellulaire. Ce changement mène à l’hyperprolifération des cellules qui se dupliquent donc de manière exagérée, entraînant la formation de tumeurs. Bien qu’ils n’aient pu expliquer comment ces mutations se sont produites, les résultats pourraient être utiles pour mettre au point des tests diagnostiques et prédictifs. De ce point de vue, un cancer — ou peut-être le risque d’apparition d’un cancer — pourrait être découvert plus tôt, ce qui mènerait à un traitement plus opportun et plus approprié.
Bien que cette étude ne constitue pas une preuve définitive et irréfutable permettant d’identifier LA cause du cancer, les résultats nous rapprochent un peu plus de la compréhension de ses multiples causes. Les données peuvent aussi nous éclairer davantage sur l’importance de faire des recherches utilisant le Big Data pour faire des découvertes uniques et utiles. À la lumière des hypothèses historiques plutôt peu pertinentes concernant la cause du cancer, cette étude révèle que nous pourrions un jour trouver la réponse à cette question millénaire.
Note de la traduction
[*] Liste des 12 cancers étudiés :
- carcinome de la vessie
- carcinome de l’endomètre (corps utérin)
- leucémie myéloïde aiguë
- adénocarcinome épithélial ovarien
- mélanome cutané
- glioblastome multiforme
- carcinome de la thyroïde
- carcinome hépatocellulaire
- carcinomes de la tête et du cou
- adénocarcinome du colon
- carcinome du poumon épidermoïde
- thymome
[1] Sudhakar A., History of Cancer, Ancient and Modern Treatment Methods. J Cancer Sci Ther, 2009. DOI : 10.4172/1948-5956.100000e2. [Publication scientifique]
[2] Raphael B. J., et al., Identifying Driver Mutations in Sequenced Cancer Genomes: Computational Approaches to Enable Precision Medicine. Genome Medicine, 2014. DOI : 10.1186/gm524. [Publication scientifique]
[3] Hastings P. J., et al., Mechanisms of Change in Gene Copy Number. Nat Rev Genet, 2009. DOI : 10.1038/nrg2593. [Publication scientifique]
[4] Chen L., et al., Pan-Cancer Analysis Reveals the Functional Importance of Protein Lysine Modification in Cancer Development. Front Genet, 2018. DOI : 10.3389/fgene.2018.00254. [Publication scientifique]
[5] Dwane L., et al., The Emerging Role of Non-traditional Ubiquitination in Oncogenic Pathways. J Biol Chem, 2017. DOI : 10.1074/jbc.R116.755694. [Publication scientifique]
[6] Wilkinson K. A. & Henley J. M., Mechanisms, Regulation and Consequences of Protein SUMOylation. Biochem J, 2010. DOI : 10.1042/BJ20100158. [Publication scientifique]
[7] Yang X. J. & Seto E., Lysine Acetylation: Codified Crosstalk with Other Posttranslational Modifications. Mol Cell, 2008. DOI : 10.1016/j.molcel.2008.07.002. [Publication scientifique]
[8] Lanouette S., et al., The Functional Diversity of Protein Lysine Methylation. Mol Syst Biol, 2014. DOI : 10.1002/msb.134974. [Publication scientifique]
Publié le 15/12/2019
Tous droits réservés © 2019 Jason Tetro/Oncobites/Aurélien Schwob/Papier-Mâché
Texte et images, à l’exception des images soumises à droits d’auteurs différents : voir au cas par cas en légende.